

Prompt-Tipp: Datenjournalismus mit KI: Karten
___STEADY_PAYWALL___
Daten sind oftmals nur eins: Zahlen, die in Tabellen und Dateien stehen. Richtigen Wert bekommen sie erst, wenn wir sie auswerten. Dann helfen sie uns auch dabei, Zusammenhänge besser zu verstehen: demographische, politische, gesellschaftliche, unternehmerische.
Und Daten machen für unsere Zielgruppen erst dann Sinn, wenn wir sie in einer ansprechenden und verständlichen Form darstellen. Eine dieser oft gewählten Formen ist die Karte - der Fokus unserer heutigen Prompt Tipps.
Vorab: Ich nutze für diesen Tipp die Pro-Version von ChatGPT für rund 20 Euro im Monat. Für diese Art der Auswertung lohnt sich das Geld aber allemal. Denn sie macht aus normalen Journalist:innen Datenjournalist:innen.
Seit einigen Wochen hat ChatGPT dafür ein eigenes Feature in seiner GPT-4-Version: “Advanced Data Analysis”.
Dieses Feature ist genau dafür da, um Daten zu analysieren und auszuwerten. Wenn wir die Funktion auswählen, können wir mit dem Plus neben der Eingabeleiste unten sogar Dateien hochladen, die wir analysieren möchten.
Und zum Glück gibt es mittlerweile viele Daten, die uns Open Source zur Verfügung stehen. Starten wir mit einem kleinen einfachen Beispiel.
Beispiel 1: Öffentliche Toiletten in München
Die Stadt München hat eine spezielle Webseite für ihre Open Source-Daten. Dort habe ich eine Übersicht der öffentlichen Toiletten der Stadt entdeckt. Diese Übersicht lade ich mir nun von der Seite herunter.
ChatGPTs Analysetool kann zahlreiche Dateiformate analysieren. Am zuverlässigsten sind aber das CSV-Format und das TXT-Format. CSV sind oft tabellarische Daten, die von den meisten Datenmanipulationstools wie Excel leicht zu lesen und zu schreiben sind. TXT-Dateien sind reine Textdateien. ChatGPT kann auch PDFs lesen, aus meiner Erfahrung aber nicht immer zuverlässig.
Ich lade die Toilettendaten also im CSV-Format hoch mit dem Ziel, diese anschaulich auf einer Karte angezeigt zu bekommen. Wie ich sehe enthält die CSV-Datei die Koordinaten der Toiletten. Das sollte für die KI also kein Problem sein. Ich formuliere folgenden Prompt:
“Bitte nutze die angehängte Datei, um eine Karte mit den Standorten der öffentlichen Toiletten in München zu erstellen.”
Die KI beginnt mit dem Analyseprozess. Und jetzt können wir der KI bei der Arbeit zusehen, denn das Tolle ist: ganz eigenständig bereinigt das Tool die bereitgestellten Daten, sodass sie für uns nutzbar sind.
Immer wieder meldet ChatGPT Probleme:
“ Versuch, die CSV-Datei zu lesen, ist ein Fehler aufgetreten. Dies könnte auf ein Problem mit dem Format der Datei hinweisen, möglicherweise aufgrund unerwarteter Trennzeichen…”
“Die Datei wurde erfolgreich geladen, aber es scheint, dass die erste Zeile die Spaltenüberschriften enthält…”
Gleichzeitig findet das Tool aber immer wieder von selbst heraus, was das Problem ist und wie es gelöst werden kann. Zum Schluss hat das Tool die Daten Schritt für Schritt so sehr bereinigt, dass eine Karte mit den Standorten erstellt werden kann. Ein Klick auf die Standorte gibt uns sogar die Namen der Toiletten bzw. deren Standort.
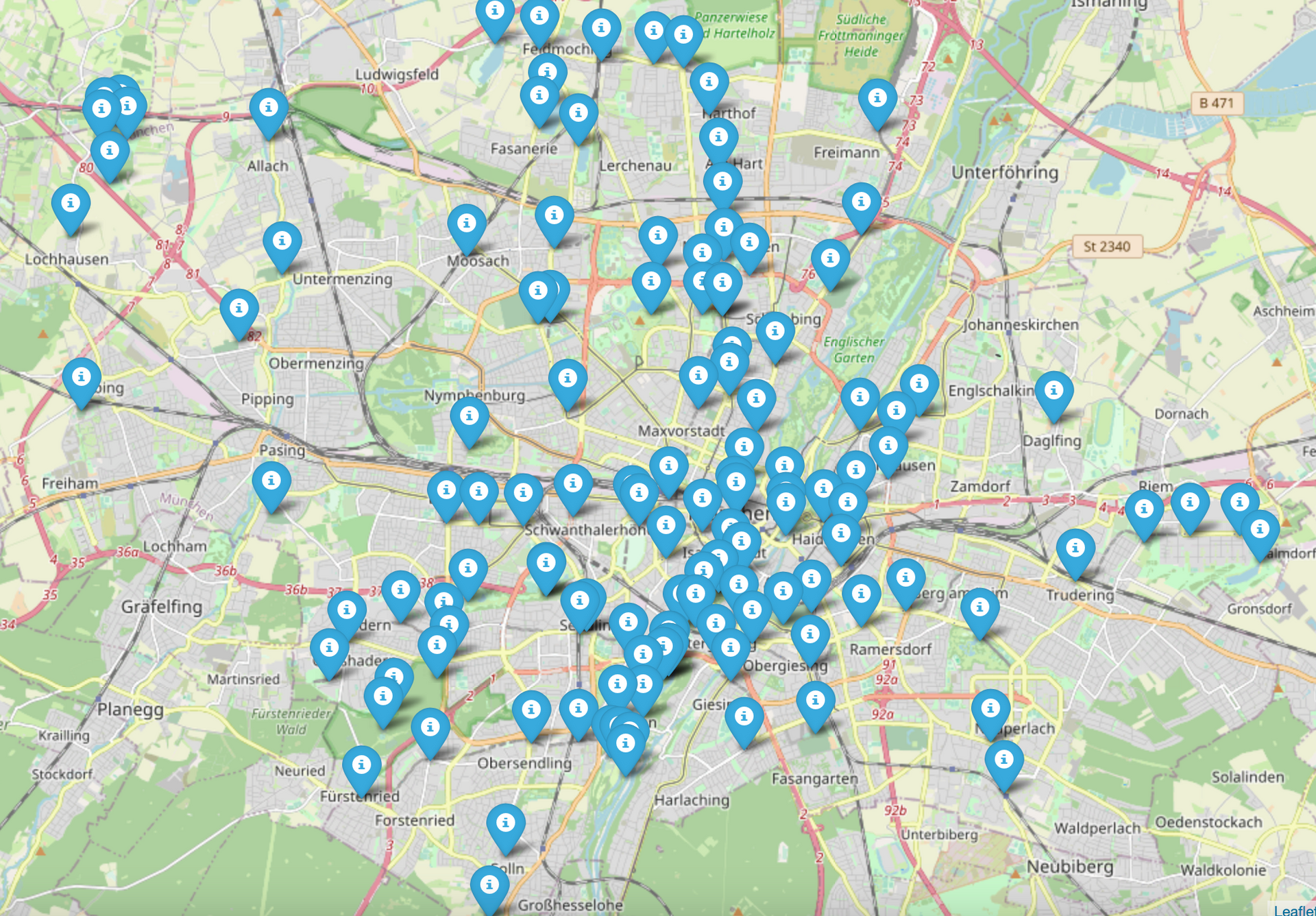
Beispiel 2: Anteil von Ausländer:innen in den Wahlkreisen
Das zweite Beispiel ist schon etwas anspruchsvoller. Ich möchte gerne eine Karte erstellen, in denen die 299 Wahlkreise der Bundestagswahl 2021 abgebildet sind. Danach möchte ich diese einfärben entsprechend ihres Anteils an Ausländer:innen in der Bevölkerung. Diese Auswertung möchte ich dann für meine Berichterstattung nutzen.
Im ersten Schritt muss ich also eine Karte erstellen, die alle Bundestagswahlkreise enthält. Auf der Seite des Bundeswahlleiters werde ich fündig und finde Open Source-Daten mit dem Titel “Karte der Wahlkreise zum Download”.
Dort finde ich unzählige verschiedene Dateiformate. Als Laie kann ich nicht einschätzen, welche ich davon benötige, also frage ich einfach die KI:
“Ich möchte eine Karte Deutschlands mit den 299 Wahlkreisen zur Bundestagswahl 2021 erstellen. Ich habe Open Source-Daten gefunden. Welche Dateien in welchen Formaten benötigst du, um die Karte zu erstellen?”
Als erstes schlägt mir das Tool “Shapefile (SHP)” vor, was ich auch auf der Seite des Bundeswahlleiters finde. Ich lade es also herunter unter erhalte einen Ordner mit vielen verschiedenen Dateien. Zunächst lade ich die Datei im SHP-Format hoch.
Ich erhalte folgende Antwort:
“Wie ich bereits erwähnte, ist ein Shapefile tatsächlich ein Set von Dateien, die zusammenarbeiten. Normalerweise gibt es mindestens drei Begleitdateien mit den Erweiterungen .shx, .dbf und .prj. Diese Dateien sind notwendig, um die geometrischen Daten korrekt zu interpretieren und darzustellen.”
Zum Glück befinden sich auch diese Dateien im Ordner. Ich lade sie also ebenfalls hoch. Nach nur wenigen Sekunden erhalte ich folgendes perfekte Bild der 299 Wahlkreise.
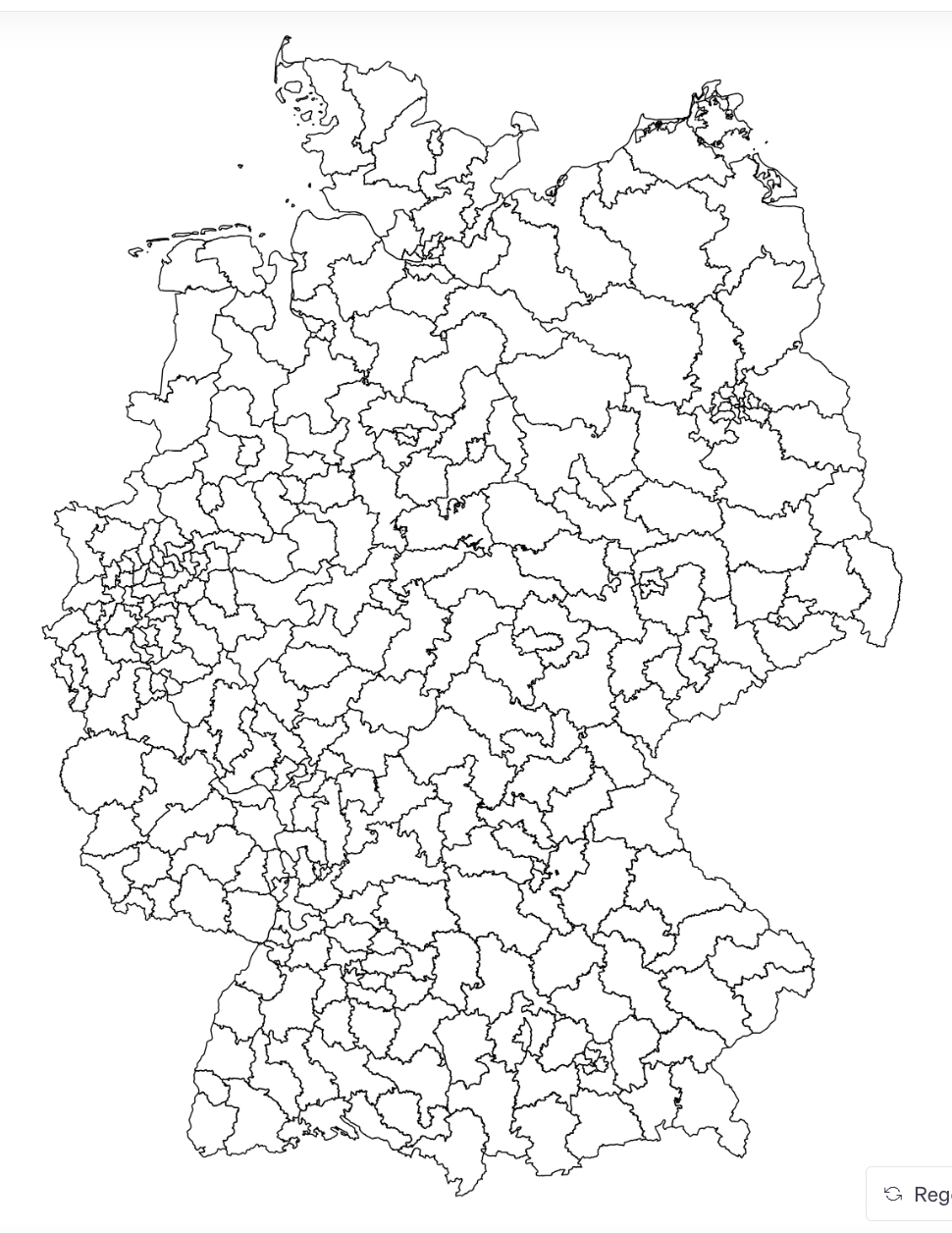
Nun möchte ich die Karte wie geplant einfärben - entsprechend dem Anteil der Ausländer:innen in den Wahlkreisen. Dafür brauche ich erneut Daten. Und ich werde fündig auf der Seite des Bundeswahlleiters. Ich finde nämlich eine Datei mit dem Namen “Strukturdaten der Wahlkreise”. Darin enthalten ist auch der Anteil der Ausländer:innen.
Ich lade die Datei hoch und gebe ChatGPT folgende Aufgabe:
“Bitte färbe die Wahlkreise ein entsprechend des Anteils der Ausländer in den verschiedenen Wahlkreisen. Du findest die Daten dazu in der angehängten Datei. Vergleiche die Nummern der Wahlkreise, um beide Datensätze zusammenzubringen.”
Erneut arbeitet das Tool vor sich hin, stößt auf Probleme, löst diese aber direkt von selbst. Nach etwa zwei Minuten habe ich folgendes - erneut perfektes - Ergebnis:
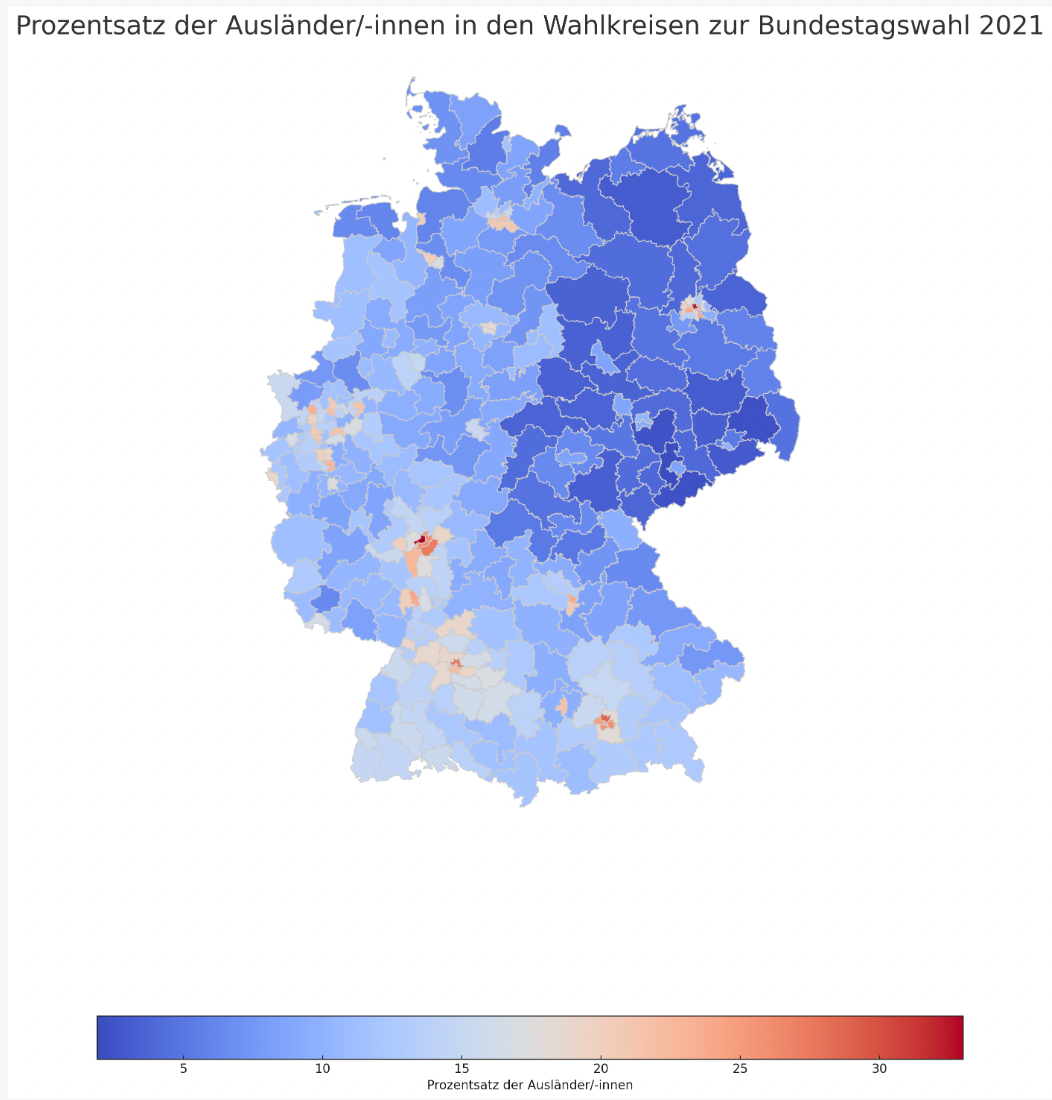
Ohne Programmierkenntnisse und ohne Erfahrung als Datenjournalist:in haben wir in wenigen Minuten Daten ausgewertet und dargestellt. Diese können wir nun direkt für unsere Veröffentlichungen nutzen oder für unsere weitere Arbeit.

