

Background: Large Language Models (LLMs)
___STEADY_PAYWALL___
Wer sich mit generativen KI-Tools beschäftigt, stößt früher oder später auf die sogenannten “Large Language Models”, die LLMs. Diese bilden die Grundlage für KI-Tools wie ChatGPT oder Bard. Doch was sind diese LLMs und wie funktionieren sie? Der Versuch einer Erklärung in einfacher Sprache:
Large Language Models sind wie riesige Wörterbücher, die von Künstlicher Intelligenz (KI) angetrieben werden. Sie lernen, menschliche Sprache zu verstehen und zu generieren, indem sie riesige Mengen an Textdaten analysieren. Stelle dir vor, ein LLM liest Millionen von Büchern und lernt dabei, wie Wörter und Sätze zusammenhängen.
Diese Modelle arbeiten mit sogenannten neuronalen Netzwerken (neural networks). Ein neuronales Netzwerk ist ein bisschen wie ein menschliches Gehirn - es besteht aus vielen kleinen Einheiten, die miteinander verbunden sind und zusammenarbeiten. Diese Einheiten können lernen, komplexe Beziehungen zwischen Wörtern zu erkennen. Sie können zum Beispiel lernen, dass das Wort "Hund" oft in der Nähe von Wörtern wie "bellen", "Schwanz" oder "Fell" vorkommt.New Paragraph
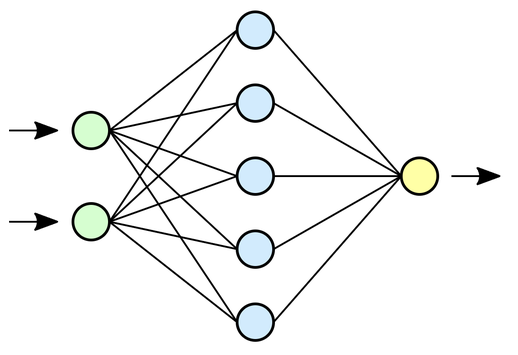
Ein wichtiger Teil dieser neuronalen Netzwerke sind die sogenannten Transformer-Netzwerke (transformer networks). Sie sind wie die Aufmerksamkeitsspanne des Netzwerks. Sie helfen dem Netzwerk, sich auf die wichtigsten Wörter in einem Satz zu konzentrieren und den Kontext zu verstehen. So kann das Netzwerk zum Beispiel erkennen, dass in dem Satz "Der Hund jagt den Ball" das Wort "jagt" wichtig ist, um zu verstehen, was der Hund tut.
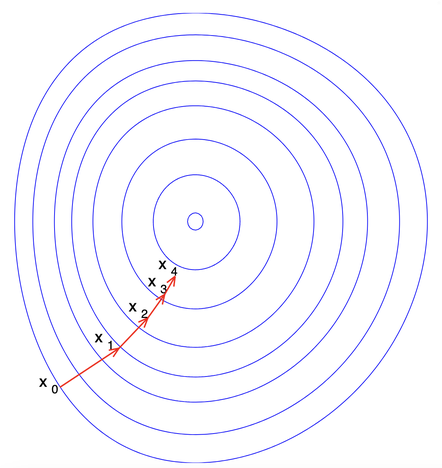
Das Training dieser Modelle ist ein bisschen wie das Training eines Hundes. Man gibt dem Modell eine Aufgabe und wenn es diese richtig löst, bekommt es eine Belohnung. Wenn es einen Fehler macht, wird es korrigiert. Dieser Prozess wird Gradientenabstieg (gradient descent) genannt. Stelle dir vor, du stehst auf einem Hügel und willst zum tiefsten Punkt im Tal. Du schaust dich um und entscheidest, in welche Richtung du gehen musst, um am schnellsten abzusteigen. Das ist im Grunde das, was beim Gradientenabstieg passiert - das Modell versucht, den schnellsten Weg zu finden, um seine Fehler zu minimieren.
Große Sprachmodelle sind die Grundlage für viele KI-Tools, die wir heute kennen, einschließlich ChatGPT. Sie ermöglichen es diesen Tools, menschliche Sprache zu verstehen und zu generieren. Dies macht sie zu leistungsstarken Werkzeugen für eine Vielzahl von Aufgaben, von der Beantwortung von Fragen über das Übersetzen von Sprachen bis hin zum Schreiben von Code.

